機械学習「クラスタリング」とは?(学習メモ)

クラスタリング
クラスタリングは、データを互いに似た者同士に分類する、教師なし学習。
たとえば、つぎの図の点を2つのクラスター、すなわち、グループに分類することを考える。

似た者同士にグルーピングすることにより、どのデータと、どのデータが似ているのかを把握することができる。

クラスタリングでは、データ間の「似ている」を、「距離」で定義する。
距離は、ユークリッド距離を使う。
図では、「×」を中心として、そこからの距離が近い2つのクラスターに分けている。
※ユークリッド距離
人が定規で測るような二点間の「通常の」距離のこと。
ユークリッド距離の例
3人の生徒の国語、数学の点数が、つぎのようにあるとする。

このとき、
・AさんとBさんの距離は、30 ( = √*1
・AさんとCさんの距離は、57 ( = √*2
・BさんとCさんの距離は、41 ( = √*3
になるので、AさんとBさんが、同じグループになる、ということ。

クラスタリングの例
・顧客がどの程度利用しているかによって、ヘビー、ミドル、ライトに分類
・気象条件による地区の分類
・得点によるグループ分け
・アンケートによる分類
クラスタリングはデータを大まかにグループ化する際に効果的。
クラスタリングはその手法から、大きく次の 2 種類に分けることができる。
階層的クラスタリング
階層的クラスタリングは、データやクラスター間の類似度に基づいてデータを 1 つのグループ(クラスター)にまとめていき、すべてのクラスターが統合されるまでこれを繰り返す手法。 クラスターに分類した結果は樹形図(デンドログラム)として表すことができる。
樹形図をある高さで切断することにより、データを複数のクラスターに分類することができる。 また、樹形図の下の下で併合したデータはその類似度が高いことを意味しており、より直感的にデータの類似度を確認することができる。
ただし、階層的クラスタリングは、分類対象データが多い場合には計算量が莫大になってしまう問題がある。大量データの場合には、非階層的クラスタリングが用いられることが多い。
非階層的クラスタリング
非階層的クラスタリングは、データやクラスター間の類似度など基づいてデータを、指定したクラスター数にまとめていく。
代表的な分析手法として、k-平均法(k-means)がある。
現在は、k-平均法を改良した k-means++ が使われている。
k-平均法
k-平均法のアルゴリズムは以下のような手順で行う。
1. ランダムに k 個のデータを中心に決める
2. k 個の中心からの距離により、データをクラスターに分類
3. クラスターの中心を計算後、クラスターを解散
4. クラスターの中心が変化しなければ計算終了、それ以外は 2 に戻る
5. このアルゴリズムによって、k 個のクラスターができる
ただ、初期の中心はランダムに決めるため、場合によっては、うまく分類できないこともある。
この欠点を改良した k-means++ 法というのもある。
scikit-learn のk-平均法では、デフォルトで、この k-means++ を使っている。

ハイパーパラメーター探索
k-平均法は、あらかじめ、いくつのクラスターに分けるかを決めておく必要がある。
この、クラスター数がハイパーパラメーターになる。
ただ、クラスターに分けてみないことには、どの程度のクラスター数が適しているかはわからない。
そこで使われるのが、エルボー図やシルエット図といったもの。
ここでは、エルボー図について、紹介。
エルボー図は、クラスター数を最初から見積もるのは難しいので、クラスター数を変えたときに、そのクラスター内の中心と点の距離の平方和(残差平方和、SSE: Sum of Squared errors of prediction) を確認していく、というように、見積もる手法。 残差平方和は、クラスター数が増えると、だんだん減少していく。
この残差平方和をプロットして、この減少具合の変わり目に着目し、クラスター数を決める、というもの。
この変わり目のところが、肘を曲げたところに似ているので、「エルボー図」と呼ぶ。
以下がエルボー図。クラスター数が増えると、残差平方和がだんだんと減っているのがわかる。

押していただけると励みになります!
機械学習「クラス分類」とは?(学習メモ)
機械学習「クラス分類」について学んだことをメモします。

- クラス分類
- クラス分類の例
- アリゴリズム「サポートベクターマシン(SVM)」
- アリゴリズム「カーネル法」
- クラス分類の分析手順
- データの準備
- クラス分類のためのモデル作成
- クラス分類のための学習
- クラス分類のための予測
- クラス分類のための評価
クラス分類の例
クラス分類の代表的な例としては、以下のようなものがある。
・顧客データによる与信審査
・メールの内容による迷惑メール判断
・がん検診によるがん診断
・手書き数字の認識
・画像の認識
など
アリゴリズム「サポートベクターマシン(SVM)」
サポートベクターマシン(SVM, Support Vector Machine)は、カテゴリを識別する境界線を、マージンが最大になるように引く分析手法。
たとえば、つぎの図にある点を2つのグループに分類することを考える。グループのことをクラスという。
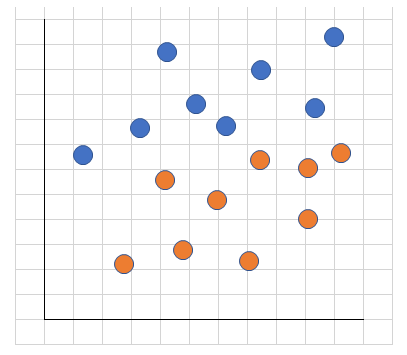
2つのクラス、すなわち、グループに分けるときに、境界線の引き方はいくつかあるが、、 それぞれのクラスの中で、境界線に近い点(サポートベクターという)との距離(マージン)が最大になるように境界線を引く。

境界線に近い点(サポートベクター)を計算すればよい、という考え方により、計算量を減らすことができる。
サポートベクターマシンでは、 ソフトマージンとハードマージンという考え方がある。
・ソフトマージン
データがマージンの中に入る可能性がある。マージンの中に入ったら、ペナルティC を与える
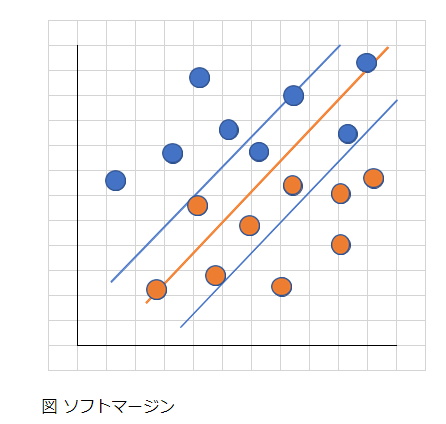
・ハードマージン
データはマージンの中に入らないことを前提

このペナルティ C は、正則化パラメーターともいい、ハイパーパラメーター(スラック変数ともいう)として定義する。
・C が小さい
誤分類のペナルティが小さい → ソフトマージン志向 → 汎用化につながるが、誤分類の可能性が高くなる
・C が大きい
誤分類のペナルティが大きい → ハードマージン志向 → 汎用化が失われ、過学習の可能性が高くなる
アリゴリズム「カーネル法」
サポートベクターマシンのアルゴリズムは、前記のように、直線を使って、クラスを分類する、というものだが、直線だけで分類できない点の配置も出てくる。そういった場合に有効なのが、カーネル法である。平たく言うと、カーネル法は2次元、3次元...など次元を変えて境界線を作り、分類する計算手法。
カーネル法では、説明変数(特徴量)を人が気にしなくても分類できるようになる。回帰分析のときは、相関係数を出して、相関の高いものを説明変数にしたが、サポートベクターマシンでは、説明変数になりえるすべての変数を使う。逆に、どの変数が分類に効いているのかは、わからない。
カーネル法を使った関数には、いくつかある。
・線形カーネル
・多項式カーネル
・RBFカーネル(ガウスカーネル)
・双曲線カーネル
一般的には、RBFカーネルを使う場合が多い。scikit-learnの関数でも、デフォルトはRBFカーネルになっている。
RBF カーネルでは、前記の正則化パラメーター C とあわせて、カーネル係数 γ を決めることが必要。 カーネル係数γの値によって、どのような分類になるかが決まる。
・γ が小さい
単純な境界 → 分類が粗くなる → ざっくりとした分類
・γ が大きい
複雑な境界 → 分類が細かくなる → モデルが複雑
RBF カーネルでは、ちょうどよい 正則化パラメーター Cとカーネル係数γ を決めていく。このような、ハイパーパラメーターは、あらかじめ人間が決めてあげる必要がある。
クラス分類の分析手順
サポートベクターマシンによる分析は、scikit-learn ライブラリでは、sklearn.svm を使う。
インポートは、以下の通り。
from sklearn import svm
なお、NumPy, pandas, Matplotlib, Seaborn については、何も言わなくてもインポートするものとする。
分析の手順は、教師あり機械学習の手順通り。
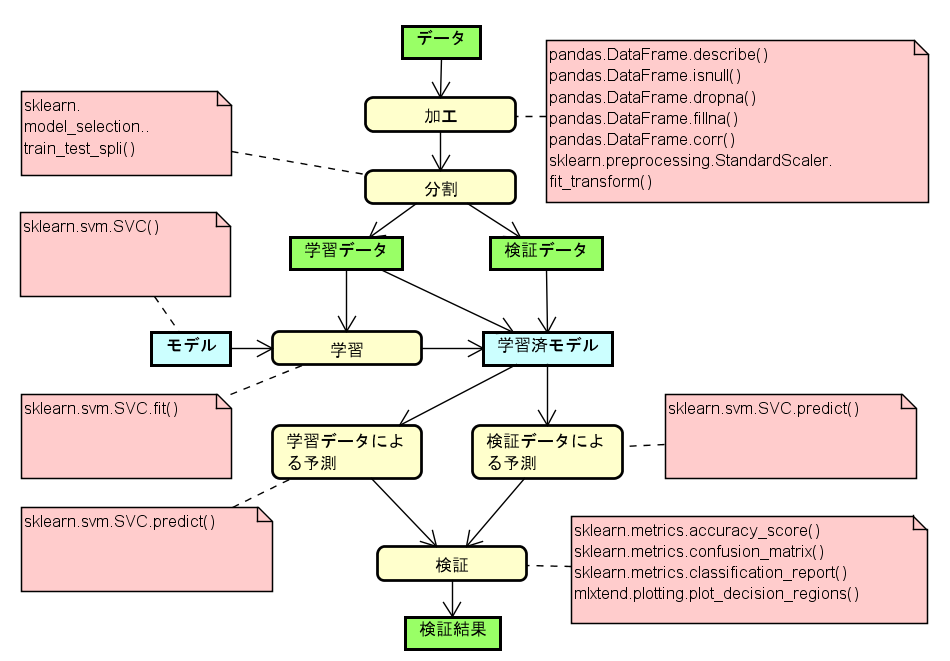
データの準備
分析の手順とAPI
サポートベクターマシンによる分析は、scikit-learn ライブラリでは、sklearn.svm を使います。
インポートは、
from sklearn import svm
です。
なお、NumPy, pandas, Matplotlib, Seaborn については、何も言わなくてもインポートするものとします。
分析の手順は、教師あり機械学習の手順通りです。
図 分析と手順
■ データの準備
分析すべきデータをCSVファイルで準備する。
必要に応じて、欠損値の処理、外れ値の処理などの前処理を行う。
なお、scikit-learn のサポートベクターマシンは、欠損値を許さないため、欠損値に対しては、何らかの処理が必要になる。
サポートベクターマシンを使った分類では、とくに相関係数をみる必要はない。すべての説明変数を使うことができる。
ただし、マシンのリソースなどの関係で、変数を減らしたいときには、主成分分析などを使って変数の数を減らす。または、目的変数が連続値の場合は、単純に、相関係数を見て、相関がなさそうなところから減らしていく。
クラス分類のためのモデル作成
まずは、クラス分類のためのモデルを作る。
サポートベクターマシンで、分類用のRBFカーネルを使い、 次のようなコードで作ることができる。
sklearn.svm.SVC(
C=1.0, # 正則化パラメーター(>0)
kernel='rbf', # アルゴリズム['linear'|'poly'|'rbf'|'sigmoid'|'precomputed'|自作)
degree=3, # kernel='poly' のときの次数
gamma='scale', # kernel=['rbf'|'poly'|'sigmoid'] のときのカーネル係数
random_state=None # 確率推定のためにデータをシャッフルするときに使用される擬似乱数ジェネレーターのシード
)
クラス分類のための学習
学習は、モデルの fit() 関数を使う。
fit(
X, # 説明変数
y, # 目的変数
sample_weight=None # 重さ
)なお、説明変数 X は、変数がひとつであったとしても、2次元の配列や、データフレームでなければならない。
クラス分類のための予測
予測は、モデルの predict() 関数を使う。
predict(
X # 説明変数
)predict() 関数で、説明変数X から、目的変数 y を計算してくれる。
クラス分類のための評価
モデルを評価する指標には以下のものがある。
・正解率
・混同行列(Confusion Matrix) から算出する指標
・クラス分類レポートにある指標
・正解率
実測値と予測値をもとに、正しく分類された割合。
sklearn.metrics.accuracy_score(
y_true, # 実測値
y_pred, # 予測値
normalize=True, # 正規化
sample_weight=None
)ただし、正解率だけでは、過学習の危険性があるため、モデルの精度は計れない。
したがって、評価の指標としては、つぎの混同行列に基づいた指標、適合率、精度 (Precision)、再現率 (Recall)、 F値 (F-measure, F-score, F1 Score) といったものを確認していく。
とくに、二値分類のときは、AUC と ROC 図 を使って、視覚的に確認することもできる。
・混同行列(Confusion Matrix)
混同行列は、クラス分類の結果をまとめた行列(表)。
モデルの予測結果に対して、正しく、または誤って分類した数の表。
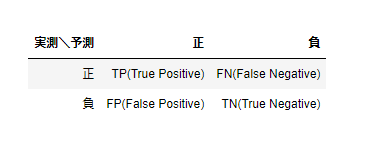
・TP(True Positive): Positive と予測して、実際に Positive だった数
・FN(False Negative): Negative と予測したが、実際は Positive だった数 (失報、見逃し)
・FP(False Positive): Positive と予測したが、実際は Negative だった数 (誤報)
・TN(True Negative): Negative と予測して、実際に Negative だった数
なお、Trueは、予測が正しかったことを意味する。Falseは、予測が正しくなかったことを意味する。
Positive や Negative は、予測すべき値。
混同行列は、以下の confusion_matrix() 関数で作成できる。
sklearn.metrics.confusion_matrix(
y_true, # 実測値
y_pred, # 予測値
labels=None, # ラベルのリスト
normalize=True, # 正規化
sample_weight=None
)よく使われる評価指標には、以下のものがある。
・正解率 (Accuracy) = (TP + TN) / (TP + FP + FN + TN)
全体のデータ中に、TP を TP に、TN を TN に、正しく分類できた割合。高いほど、性能がよい。
sklearn.metrics.accuracy_score() 関数で取得可
・適合率、精度 (Precision) = TP / (TP + FP)
正と分類したものの中で実際に正だった割合。高いほど、間違った分類が少ない。
・再現率 (Recall) = 真陽性率 (TPR, True positive rate) = 感度 (Sensitivity) = TP / (TP + FN)
本来、正と予測するデータが、どの程度、正と予測できたかの割合。高いほど、性能がよい。間違えて正と判断する割合が少ない。ただし、適合率と再現率とはトレードオフの関係にある。
・F値 (F-measure, F-score, F1 Score) = 2 / (1 / Precision + 1 / Recall)
適合率(Precision) と再現率(Recall) のバランスが保たれているかの指標。適合率(Precision) と再現率(Recall) の調和平均。高いほど、バランスが取れている。
・クラス分類レポート
混同行列は、目的変数が2値だけではなく、3つ、4つと、複数のクラスに分けることができる。
3つ以上のクラスに分けたときに、どの変数を正(True)とするのかで、前記の指標が違ってくる。
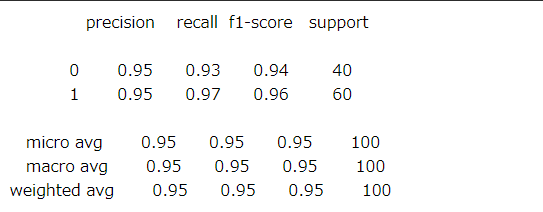
そこで、metrics.classification_report() 関数が用意されている。
これは、前記の混同行列から計算される指標のうち、以下の値を出力する。
・適合率, 精度 (Precision)
・再現率 (Recall) = 真陽性率 (TPR, True positive rate)
・F値 (F-measure, F-score, F1 Score)
二値分類のときはもちろんのこと、三値以上の分類の評価指標も可能。
sklearn.metrics.classification_report(
y_true, # 実測値
y_pred, # 予測値
labels=None, # ラベルのリスト
target_names=None, # ラベルの表示名
sample_weight=None, #
digits=2, # 出力時に丸める桁数
output_dict=False, # 出力を辞書にする
zero_division='warn'
)
押していただけると励みになります!
Pythonライブラリ「scikit-learn」とは?関数一覧(学習メモ)
Pythonライブラリ「scikit-learn」について学んだことをメモします。

scikit-learn (サイキットラーン)

Pythonで機械学習をする際によく使われるライブラリ。
回帰分析、クラス分類、クラスタリングなどの機械学習を行うことができる。
scikit-learnはオープンソース(BSD license)で公開されており、個人/商用問わず、誰でも無料で利用することができる。
scikit-learn添付のデータセット
scikit-learn には、機械学習を試してみるためのデータセットがあらかじめ用意されており、初心者の練習に向いている。
あらかじめ学習データと研修データにわけてある。
・ボストン市の住宅価格データ(Boston house prices dataset)
・回帰向き
・アヤメの品種データ(Iris plants dataset)
・分類向き
・糖尿病患者の診療データ(Diabetes dataset)
・回帰向き
・数字の手書き文字データ (Optical recognition of handwritten digits dataset)
・分類向き
・生理学的特徴と運動能力の関係についてのデータ(Linnerrud dataset)
・回帰向き
・目的変数が3つある
・ワインの品質データ(Wine recognition dataset)
・分類向き
・乳がんデータ(Breast cancer wisconsin (diagnostic) dataset)
・分類向き
scikit-learnの6つの機能
scikit-learnの6つの具体的な機能は以下のとおり。
①回帰
二種類ある教師あり学習のうちの一つで、データセットを学習して新たな入力に対する出力の数値を予測する手法のこと。例えば、過去の気象データと位置情報を学習し、その地点の翌日の気温を予測する際には回帰を行う。
②分類
分類はもう一つの教師あり学習で、データを学習して、新たな入力に対する出力のラベルを予測する手法のこと。回帰と同様に気象に関して例えるならば、過去の気象データと位置情報を学習し、その地点の翌日の天気(晴れ、曇り、雨、雪)を予測するのは、分類。
以下、分類や回帰に用いることができるscikit-learnのアルゴリズムの例。
・線形モデル
・サポートベクターマシン
・確率的勾配降下法
・最近傍
・ガウス過程
・決定木
・アンサンブル学習
・ニューラルネットワーク
③クラスタリング
データの特徴から関連の深いデータや似通ったデータを見つけ、クラスターに分ける(=グルーピングする)手法。例えば、企業の購買データの分析などに応用されていて、クラスタリングの結果に基づいて顧客に商品をレコメンドできる。scikit-learnでは、クラスタリングもK-meansをはじめ数多くのアルゴリズムで実行可能。
④次元削減
次元削減は教師なし学習の一種。データセットの特徴量同士の関係を学習し、より簡潔かつ効率的に特徴量の情報を表現することなどを目的に、新たな特徴量を計算で導出して特徴量の数を削減する手法。例えば、近年盛んに様々なメディアで取り上げられているビッグデータを処理する際に、データセットのあまりの大きさにコンピュータの処理性能が不足することがあります。そういった場合に、次元削減をすることでコンピュータの性能不足を補うことができる。scikit-learnでは、主成分分析や因子分析などで次元削減を行うことができる。
⑤データの前処理
データの前処理といっても、pandasで行うようなデータの整形ではなく、機械学習が正しく実行されるためのデータの数値変換を行う。適切な前処理を行うことで、特定の特徴量が学習結果に過大な影響を与えることなどを防ぐことができる。例えば、データの平均を0、標準偏差を1にする標準化などを行う。なお、scikit-learnでは他にも、非線型変換や正規化、離散化などの処理を行うことができる。
⑥モデルの評価と選択
様々な手法・モデルを用いて機械学習を実装できるため、モデルを正しく評価して、どのモデルを使うのか選択する必要がある。そのために、scikit-learnには、各種評価指標を簡単に算出したり、ハイパーパラメータをチューニングしたりするための機能が備わっている。
プログラミング、私のアウトプット学習法。
プログラミング初心者です。
プログラミング言語Pythonをもちいて、現在は機械学習に必要なライブラリの使用方法について学習を進めています。
インプット学習としては、ウェブ講習資料を読み、まとめサイトやブログ、Youtubeでわかりやすい解説を読んで理解しています。
本日はアウトプット学習方法について簡単に紹介します。

学んだ事項をブログにまとめる
ただ読んだだけではわかったようなわからないような、あいまいな状態になるので、このブログで学んだことを書き込むことで頭の整理になっています。
ただし、コードのコピペだとやはり読んだだけ状態と変わらないので、なるべく理解できるように一文字一文字を打ち込むよう努力しています。
印刷物に書き込む
少し面倒ですが、代表的なプログラミングコードの羅列をどこからか引っ張ってきて、Google Coraboratoryに貼り付け、計算やグラフ描画を実行。そのコードの意味とアウトプットを照らし合わせるために、紙に印刷してペンでメモ書きしています。
どうしても、学校教育では紙とペンで書き込むことで頭に入れる習慣がついてしまっているので、こうしたアナログな方法は一番頭に入りやすいです。
Youtubeの出題番組で、応用例で実践
https://youtu.be/bsYJ3hTvx7c
こちらのサイトでは、「20本ノック」といって、Pythonライブラリに関するコードの初歩の練習問題を20題だしてくれます。この問題に従って、自分なりに調べてコードを書き、答え合わせすることで、スムーズに記憶されていっています。
以上、簡単ですが、プログラミング初心者の、Pythonライブラリアウトプット学習法を紹介いたしました。
参考になれば幸いです。
押していただけると励みになります!
Pythonライブラリ「Matplotlib」とは?関数一覧(学習メモ)
ライブラリ「Matplotlib」について学んだことをメモします。

- Matplotlib(マットプロットリブ)
- 似てるけど違うseaborn(シーボーン)
- グラフを描く基本的な手順
- レイアウトの設定
- 折れ線グラフ
- 直線グラフ
- 棒グラフ
- ヒストグラム
- 散布図
- 散布図行列
- 箱ひげ図
- ヒートマップ / クラスターマップ
- 画像や2次元配列の表示
Matplotlib(マットプロットリブ)

データの可視化(グラフ化)ができるコードを揃えたライブラリ。
Matplotlibで出力できるグラフ例:
・折れ線グラフ
・棒グラフ
・ヒストグラム
・散布図
・散布図行列
・ヒートマップ
・クラスターマップ
・箱ひげ図
インポート方法は以下のとおり。
import matplotlib.pyplot as plt
似てるけど違うseaborn(シーボーン)

可視化ライブラリにはもう一つ、seabornが知られる。単純に言うと、Matplotlibよりも使い勝手を良くしてグラフをかっこよくしたものがseabornらしい。
インポート方法は以下のとおり。
import seaborn as sns
seaborn内でmatplotlibを使えることから、以下のようにパッケージとしてインポートすると楽。
# ビジュアル化関係のパッケージ import matplotlib.pyplot as plt import seaborn as sns sns.set() # seaborn使用の設定
グラフを描く基本的な手順
1.グラフを書く「軸」と、それを配置する「図」のインスタンスを取得する。
2.「軸」単位にグラフを描画する。
fig, ax = plt.subplots() # 図と軸インスタンス取得 ax.plot([y[0], y[1]], …) # 軸単位のグラフの設定 ax.set_title(‘Line graph’) # タイトル設定 ax.legend() # 凡例表示 plt.show() # 描画
・図と軸を1x1で取得したい場合
fig, ax = plt.subplots() # 図と軸(1x1)インスタンス取得

・図と軸を1x2で取得したい場合
fig, ax = plt.subplots(1, 2) # 図と軸(1x2)インスタンス取得

・図と軸を2x1で取得したい場合
fig, ax = plt.subplots(2, 1) # 図と軸(2x1)インスタンス取得

・図と軸を2x2で取得したい場合
fig, ax = plt.subplots(2, 2) # 図と軸(2x2)インスタンス取得

レイアウトの設定
画像を大きくしたり小さくしたり、 タイトルとグラフが重なってしまうので、余白を大きくしたいなど、デフォルトのデザインを変更する場合は、matplotlib.pyplot.rcParams に設定する。
matplotlib.pyplot.rcParams['設定したいキー'] = 値
例えば、画像サイズを変える場合は以下のとおり。
plt.rcParams['figure.figsize'] = (16.0, 16.0) # 画像サイズの設定
折れ線グラフ
matplotlib.lines.Line2D(xdata, ydata, linewidth=None, linestyle=None, color=None,
marker=None, markersize=None, markeredgewidth=None,
markeredgecolor=None, markerfacecolor=None,
markerfacecoloralt='none',fillstyle=None, antialiased=None,
dash_capstyle=None, solid_capstyle=None,
dash_joinstyle=None, solid_joinstyle=None, pickradius=5,
drawstyle=None, markevery=None, **kwargs)・xdata (必須) X 軸方向の数値
・ydata (必須) Y 軸方向の数値
・linewidth 線の太さ
・linestyle 線のスタイル。
‘solid’ (実線), ‘dashed’ (破線), ‘dashdot’ (破線&点線), ‘dotted’ (点線) から指定。
(デフォルト値:”solid”)
・color 線の色
・marker マーカーの種類。参考: matplotlib.markers (デフォルト値:”None”)
・markersize マーカーの大きさ
・markeredgewidth マーカーの枠線の太さ
・markeredgecolor マーカーの枠線の色
・markerfacecolor マーカーの塗りつぶしの色
・markerfacecoloralt マーカーの塗りつぶしの色 2。
fillstyle で left, right, bottom, top を指定した際、
塗りつぶされない領域が ‘markerfacecoloralt’ で指定された色となる。
(デフォルト値: ‘none’)
・fillstyle マーカーの塗りつぶしのスタイル。
‘full’ (全体), ‘left’ (左半分), ‘right’ (右半分), ‘bottom’ (下半分),
‘top’ (上半分), ‘none’ (塗りつぶしなし) から選択。
・antialiased アンチエイリアス (線を滑らかに描画する処理) を適用するかどうか。
False または True から選択。
データフレームに2列あれば、その2列分が折れ線として表示される。
以下は、weatherというデータファイルの「ave_temp」「ave_vapor_pressure」を2軸として折れ線グラフを描く場合。
weather[['avg_temp', 'avg_vapor_pressure']].plot.line()

直線グラフ
Axes.plot([x0, x1], [y0, y1]) と記述すると、点(x0, y0) から 点(x1, y1) まで直線が引かれる。
fig, ax = plt.subplots() # 図と軸を取得 ax.plot([0, 12], [0, 12]) # 45度線

棒グラフ
以下は、weatherというデータファイルの「ave_temp」「ave_vapor_pressure」を棒グラフを描く場合。
weather[['avg_temp', 'avg_vapor_pressure']].plot.bar()

plot引数をつかうと、軸を指定できる。
fig, ax = plt.subplots(1, 2) # 図と軸(1x2)を取得 weather[['avg_temp']].plot.barh(ax=ax[0]) weather[['avg_vapor_pressure']].plot.bar(ax=ax[1])

subplots=True で、列ごとに軸を分割することもできる。
weather[['avg_temp', 'avg_vapor_pressure']].plot.bar(subplots=True) # subplots=True で、列ごとに軸を分割


散布図
以下は、weatherというデータファイルで、x軸に「平均気温: avg_temp」、y軸に「平均蒸気圧: avg_vapor_pressure」を指定して、散布図を描く場合。
weather.plot.scatter(x='avg_temp', y='avg_vapor_pressure')

散布図行列
変数が2変数のときは、散布図でよいが、3変数以上になると、いちいち、変数の組み合わせを作り、散布図を描く必要があり面倒なので、散布図行列にすると楽。
以下は、weatherというデータファイルのすべての変数の散布図行列を描く場合。
sns.pairplot(weather.drop('pref_code', axis=1))
箱ひげ図
matplotlibの箱ひげ図は、外れ値の確認をするのに便利
箱ひげ図のグラフの見方。
・25パーセンタイル=第一四分位数
・50パーセンタイル=第二四分位数
・75パーセンタイル=第三四分位数

以下は、weatherというデータファイルのすべての変数の箱ひげ図を描く場合。
weather.drop('pref_code', axis=1).boxplot(rot=90) # ID列以外を指定
plt.show()
ヒートマップ / クラスターマップ
多変数の相関係数を比較するのに、わかりやすくビジュアル化する際使う。
ヒートマップは、データフレームの行の順番通りに出力するが、クラスターマップは、樹形図を追加するため、樹形図が見やすくなるように、変数の順番が入れ替わる。
r = weather.drop('pref_code', axis=1).corr()
sns.heatmap(r.round(1), annot=True) # ヒートマップ
plt.title('heatmap')
plt.show()
sns.clustermap(r.round(1), annot=True) # クラスターマップ
plt.title('clustermap')
plt.show()

画像や2次元配列の表示
画像や2次元配列を表示する。3次元目は、RGB値やRGBA値を指定。省略したときは、グレースケール。
X については、以下のような2次元または3次元の配列になる。
・(M, N):スカラーデータを含む画像。データはカラーマップを使用して視覚化。
・(M, N, 3):RGB値(0-1 floatまたは0-255 int)の画像。
・(M, N, 4):RGBA値(0-1 floatまたは0-255 int)の画像、つまり透明度を含む。
img = np.linspace(0, 1.0, 25).reshape(5, 5) # 5x5 の配列 print(img) plt.imshow(img) plt.gca().grid(False)

押していただけると励みになります!
Pythonライブラリ「pandas」とは?関数一覧(学習メモ)
Pythonライブラリ「pandas」について学んだことをメモします。

- pandas(パンダス)
- pandasの2つのデータ構造、「Series」「DataFrame」とは
- Seriesを定義する
- DataFrameを定義する
- head関数
- tail関数
- 統計量を確認する関数
- 相関係数
- データの取り出し
- クロス分析
- データフレームの定義とデータの追加
- 結合
- ソート
- 欠損値の処理
pandas(パンダス)
csvファイルやExcelファイルデータの読み込み、並び替え、欠損値補完などができるPythonのライブラリ。数表および時系列データを操作するためのデータ構造と演算を提供する。
pandasのライブラリのインポートは、以下のように記述するのが一般的。
別名として、「pd」とする慣習がある。
import pandas as pd
pandasの2つのデータ構造、「Series」「DataFrame」とは
Pandas(パンダス)には2つの主要なデータ構造があり、Series(シリーズ)が1次元のデータ、DataFrame(データフレーム)が2次元のデータに対応する。
Seriesを定義する
基本的には以下のコードで定義する。
pd.Series (data=データの配列, index=インデックスの配列, name=列名)
Seriesの情報(形状、インデックス、値、要素の値)などは、次のコードで取得できる。
In[0]:
s1 = pd.Series([1, 2, 3])
print('s1:', s1, sep='\n') # s1自体
print('s1.shape:', s1.shape) # s1の形状
print('s1.index:', s1.index) # s1のインデックス
print('s1.values:', s1.values) # s1の値
print('s1[1]:', s1[1]) # s1の値Out[0]:
s1:
0 1
1 2
2 3
dtype: int64
s1.shape: (3,)
s1.index: RangeIndex(start=0, stop=3, step=1)
s1.values: [1 2 3]
s1[1]: 2
変数の中には、値そのものではなく、値に対して、整数を割り当てたものもある。
例えば、男性が 0 で、女性が 1 や、 天気で、晴は 0、曇は 1、雨は 2 など。
こうした記号化した変数の値に対して、人間が分かりやすいように、1 であれば曇、と表示することができる。
In[0]:
df = pd.DataFrame([0, 1, 2, 1, 2, 2, 0]) # DataFrameの定義
df[0].map({0: '晴', 1: '曇', 2: '雨', }) # Seriesにするため、インデックス0を指定Out[0]:
0 晴
1 曇
2 雨
3 曇
4 雨
5 雨
6 晴
Name: 0, dtype: object
DataFrameを定義する
データフレームにCSVファイルからデータを読み込むには、以下のようにpandas.read_csv() 関数を使う。
pandas.read_csv(
CSVファイルのパス,
sep=',', # 項目の分離付
header=0, # ヘッダーの行番号(0相対)。ヘッダーなしのときは None
nrows=None, # 先頭から、指定した行数だけ入力。すべてのときは None
names=None, # [列名のリスト] で、列名を指定
dtype=None, # {列名: データ型} で、指定列が指定したデータ型で読み込まれる
encoding=‘utf-8’ # ファイルの文字コード
)
head関数
データ数が多い場合は、head関数により、先頭行から何行目までを表示する、ということが指定できる。
( )内に表示したい行数を入れる。何も入れないとデフォルトで5行表示される。
data.head() # 最初の5件を表示
tail関数
head関数と同じように、こちらは最後から何行目までを表示する、ということが指定できる。
( )内に表示したい行数を入れる。何も入れないとデフォルトで5行表示される。
data.head(10) # 最後の10件を表示
統計量を確認する関数
データ分析を行う前に、統計量の確認をする場合に用いる関数一覧を示す。
欠損値以外の行数や、合計値、平均値など、個別の関数が用意されている。
・count() 行数
・sum() 合計値
・mean() 平均値
・std() 標準偏差
・var() 分散
・min() 最小値
・max() 最大値
上記は個別に統計量を確認する関数だが、統計量のサマリーを表示する関数としてdescribe() 関数がある。
・describe() 統計量のサマリー表示
data.describe()
相関係数
変数間の相関係数は、 corr() 関数で出すことができる。回帰分析などでよく使う。
corr() 関数の結果は、相関行列で出力され、縦軸・横軸に変数が並び、その変数間の相関係数が一覧となっている。
data.corr()
データの取り出し
データ処理のために、特定の列を取り出すことがある。
その際、取り出す構造がデータフレームか、NumPy配列かによって、書き方が変わる。
データフレームとして取り出す場合は、辞書から値を取り出すイメージで以下のように記述する。
例:weatherというデータ変数から、pref_codeというデータの初めの5行を表示する。
weather['pref_code'].head()
NumPy配列として取り出す場合は、loc を使う。
例:weatherというデータ変数から、pref_codeという列データの初めの5行を表示する。
weather.loc[:, ['pref_code']].head()
locやilocを使うことで、要素を取り出せる。
基本的に、loc[インデックス名, カラム名] または、iloc[インデックス番号, カラム番号] として取得する。
例:14番目の行である「東京」のave_temp(平均気温)を指定して表示する。
weather.loc[14, 'avg_temp'] # 東京(14)の平均気温
例:3番目の行の、5番目の列を指定して表示する。
weather.iloc[3, 5]
query関数で、条件に合致したデータを取り出すこともできる。
例:wetherというデータ変数中の、ave_temp(平均気温)が18℃以上を表示する。
weather.query('avg_temp >= 18') # 平均気温が18度以上
idxmin()関数で最小値、idxmax()関数で最大値を取得できる。
例:weatherデータのすべての最小値を表示する。
weather.idxmin()
クロス分析
クロス分析とは、数あるデータの中から、2~3個のデータだけをピックアップし、それらの関係を見る分析。クロス分析では、pivot_table()関数を使い、ピボットテーブル(データ関係が見やすいシンプルな一覧)を表示できる。
DataFrame.pivot_table(
values=None, # 集計対象
index=None, # 行
columns=None, # 列
aggfunc='mean', # 集計関数
fill_value=None, # 欠損値を置き換える値
margins=False, # 小計などの行や列を追加
dropna=True, # NaNのある列を削除
margins_name='All', # margins=True のときの行や列名
)例:weather2データ中の、symbol_weather(天気記号)ごとに、count(件数)とnp.mean(平均値)を出す。その際、小数点以下1桁で表示。
weather2.pivot_table(index='symbol_weather', aggfunc=('count', np.mean)).round(1)
データフレームの定義とデータの追加
列を追加するのは、Python辞書と同様に、列名をキーとして、辞書にリストを追加していくイメージ。 最初に、空のデータフレーム(インデックス指定)をつくり、そこに、新しい列を代入で追加していく。
# 列を追加していく場合 evaluation = pd.DataFrame(index=['評価値1', '評価値2', '評価値3', ]) evaluation
# 列を追加 evaluation['モデル1'] = ['値11', '値21', '値31', ] evaluation['モデル2'] = ['値12', '値22', '値32', ] evaluation

行の追加は、列の追加に比べると、少し複雑。最初に、空のデータフレーム(カラム指定)をつくり、そこに、新しい行をappend() 関数で追加していく。 このとき、行となるのは、pandas の Series または、DataFrameとなる。1行ずつの追加と考えると、Series になる。
Series には、データフレームの列名のリストをインデックスに、また、データフレームのインデックスとして、name 引数に値を指定しておく。
name 引数を指定する必要がなければ、ignore_index=True を指定する。
# 行を追加していく場合 evaluation = pd.DataFrame(columns=['評価値1', '評価値2', '評価値3', ]) evaluation
# 行を追加 evaluation = evaluation.append(pd.Series(['値11', '値12', '値13', ], index=evaluation.columns, name='モデル1')) evaluation = evaluation.append(pd.Series(['値21', '値22', '値23', ], index=evaluation.columns, name='モデル2')) evaluation

結合
SQLのように、データフレームを結合することができる。結合条件は、指定された列の値の一致による。SQLの結合と同様に、内部結合、外部結合(左、右、完全)が指定できる。
※SQL:データベースを操作するための 言語。
DataFrame.merge(
right, # 右側に結合するデータフレーム
how='inner', # {'left', 'right', 'outer', 'inner'} ... 左外部結合、右外部結合、完全外部結合、内部結合
on=None, # 結合する列名が同じときの列名
left_on=None, right_on=None, # 結合する列名が違うときの左側と右側の列名
)
ソート
データフレームをソートすることができる。 値をもとにソートするのが、sort_values()、インデックスをもとにソートするのが、sort_index()。
・値によるソート
sort_values() 関数により、値によるソートができる。キーが複数あるときは、by引数やascending引数をリストにする。
DataFrame.sort_values(
by, # ソートする列名/行
axis=0, # ソートする軸
ascending=True, # Trueのとき、昇順
inplace=False, # オリジナルの置き換え
na_position='last', # NaNの位置
ignore_index=False # Trueのとき、インデックスが [0, 1, 2, ...] に振りなおされる
)
・インデックスによるソート
インデックスによるソートも同様の方法。
DataFrame.sort_index(
axis=0, # ソートする軸
ascending=True, # Trueのとき、昇順
inplace=False, # オリジナルの置き換え
na_position='last', # NaNの位置
ignore_index=False # Trueのとき、インデックスが [0, 1, 2, ...] に振りなおされる
)
欠損値の処理
欠損値は、何らかの原因で、欠落してしまったデータのこと。欠損値があると、正しくデータの分析ができないこともある。したがって、欠損値に対して、何かしらの処理が必要になる。処理としては、
・欠損値を含む行を削除(欠損値が特定列の場合も含む)
・欠損値を含む列を削除
・欠損値を穴埋めする
が挙げられる。
欠損値があるか確認するコード。
DataFrame.isnull()
isnull() の結果は、それぞれの要素が True/False になりますので、これと合わせて、sum() 関数を適用して、列ごとにNaNがいくつあるかを数えたりする。
DataFrame.isnull().sum()

欠損値に対する処理として、欠損値のある行を削除/列を削除することもある。 ただし、単に削除するだけでは、データ分析する上で、データが不足する可能性もあるため注意。
DataFrame.dropna(
axis=0, # 軸
how='any', # 'any':NA値が存在する場合、その行または列をドロップ
# 'all':すべての値がNAの場合、その行または列をドロップ
thresh=None, # 指定した数の非NaN値を確保
subset=None, # 特定の列(行)にNaNがある行(列)を削除する場合に指定
inplace=False # オリジナルを置き換えるかどうか
)
特定の値で欠損値を穴埋めすることもできる。
DataFrame.fillna() を使う。 データの状態にもよるが、平均値や中央値での穴埋めや、欠損値のある行の前後の値での穴埋めができる。
DataFrame.fillna(
value=None, # 特定の値を指定: すべて同じ値
# 辞書を指定: 列ごとに値を指定
# mean()などのメソッドを使うと、列ごとの平均値で置き換え
method=None, # {‘backfill’, ‘bfill’, ‘pad’, ‘ffill’, None},
axis=None,
limit=None,
inplace=False
)
・backfill: : 後ろの値で置き換え
・bfill: : 後ろの値で置き換え
・ffill: : 前の値で置き換え
・pad: : 前の値で置き換え
押していただけると励みになります!
Pythonライブラリ「NumPy」とは?関数一覧(学習メモ)
ライブラリ「NumPy」について学んだことをメモします。
NumPy(ナムパイ)
数値計算や多次元配列などを効率的に処理するライブラリ。
機械学習でよく使う2次元配列や、さらに高次元の配列を用いる場合は必ず使用する。
NumPyのライブラリのインポートは、以下のように記述するのが一般的。
別名として、「np」とする慣習がある。
import numpy as np
array()関数で配列を定義する
Pythonリストをもとに、numpy.array() を使って定義する。
array(行,列)で定義する。
※行と列の考え方
1行4列の行列 → [1,2,3,4]
4行3列の行列 → [1,2,3]
[4,5,6]
[7,8,9]
[10,11,12]
例えば、「1,2,3,4,5,6」という配列を定義したい場合は以下のとおり。
In [0]:
# 1次元配列 array1 = np.array([1, 2, 3, 4, 5, 6]) # 1次元配列 array1
Out [0]:
array([1, 2, 3, 4, 5, 6])
例えば、「1,2,3」「4,5,6」という二次元配列を定義したい場合は以下のとおり。
In [0]:
# 2次元配列 array2 = np.array([[1, 2, 3], [4, 5, 6]]) # 2次元配列 array2
Out [0]:
array([[1, 2, 3],
[4, 5, 6]])
例えば、(「1,2,3」「4,5,6」)(「7,8,9」「10,11,12」)という三次元配列を定義したい場合は以下のとおり。
In [0]:
# 3次元配列 array3 = np.array([[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]]) # 3次元配列 array3
Out [0]:
array([[[ 1, 2, 3],
[ 4, 5, 6]],
[[ 7, 8, 9],
[10, 11, 12]]])
配列の次数を確認したい場合は、インスタンス変数 shapeを使う。
In [0]:
array1.shape # 次数の確認
Out [0]:
(6,)
reshape()関数で次元を変形する
配列を指定した次数に変形する場合、reshape関数を使う。
このとき、変形後の次数のうち、ひとつを-1 と指定することで、自動的に次数が計算される。
In [0]:
array1.reshape(-1, 2) # (6,) を (3, 2) にする
Out [0]:
array([[1, 2],
[3, 4],
[5, 6]])
※2列のみ指定することで、行数を2行に自動変換してくれる。
In [0]:
array3.reshape((2, -1)) # (2, 2, 3) を (2, 6) にする
Out [0]:
array([[ 1, 2, 3, 4, 5, 6],
[ 7, 8, 9, 10, 11, 12]])
※2行のみ指定することで、列数を6列に自動変換してくれる。
arange() 関数で指定した数列を出す
開始値と終了値(終了値は入らない)と、公差(デフォルト1)を指定した数列を返す。
In [0]:
# 0から9まで np.arange(10)
Out [0]:
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
In [0]:
# -1 から 1 まで、0.2 きざみ np.arange(-1.0, 1.0, 0.2)
Out [0]:
array([-1.00000000e+00, -8.00000000e-01, -6.00000000e-01, -4.00000000e-01,
-2.00000000e-01, -2.22044605e-16, 2.00000000e-01, 4.00000000e-01,
6.00000000e-01, 8.00000000e-01])
linspace() 関数で指定した数列を出す
開始値と終了値(デフォルトで入る)と、個数(デフォルト50)を指定して、数列を返す。
引数 retstep=True とすると、そのときの公差もあわせて返す。
In [0]:
# 0から10まで、10個分 np.linspace(0, 10, 10)
Out [0]:
array([ 0. , 1.11111111, 2.22222222, 3.33333333, 4.44444444,
5.55555556, 6.66666667, 7.77777778, 8.88888889, 10. ])
In [0]:
# 0から10(入らない)まで、10個分 np.linspace(0, 10, 10, endpoint=False)
Out [0]:
array([0., 1., 2., 3., 4., 5., 6., 7., 8., 9.])
In [0]:
# 公差も返す(結果はタプル) np.linspace(0, 10, 10, retstep=True)
Out [0]:
(array([ 0. , 1.11111111, 2.22222222, 3.33333333, 4.44444444,
5.55555556, 6.66666667, 7.77777778, 8.88888889, 10. ]),
1.1111111111111112)
押していただけると励みになります!